If you have an interest in agentic coding, there's a pretty good chance you've h...

This article is divided into three parts; they are: • Floating-point Numbers • A...

This article is divided into two parts; they are: • Using `torch.

This article is divided into two parts; they are: • Data Parallelism • Distribut...

Predicting the future has always been the holy grail of analytics.

This article is divided into six parts; they are: • Pipeline Parallelism Overvie...
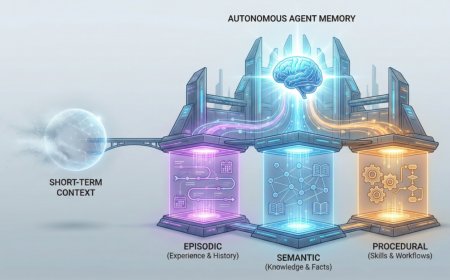
If you've built chatbots or worked with language models, you're already familiar...

This article is divided into five parts; they are: • Introduction to Fully Shard...

This article is divided into five parts; they are: • An Example of Tensor Parall...

Editor's note: This article is a part of our series on visualizing the foundatio...

Google 2025 recap: Research breakthroughs of the year

This article is divided into two parts; they are: • Simple RoPE • RoPE for Long ...

This article is divided into three parts; they are: • Training a Tokenizer with ...
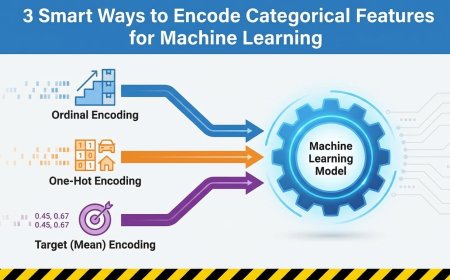
If you spend any time working with real-world data, you quickly realize that not...

Agentic coding only feels "smart" when it ships correct diffs, passes tests, and...

Large language models (LLMs) like Mistral 7B and Llama 3 8B have shaken the AI f...